Tag: C#
When I was first starting out a couple of years ago I didn’t really track my performance beyond the simple report that IB generates. Eventually I moved on to excel sheets which grew to a ridiculous and unmanageable size. I took a look at tradingdiary pro, but it wasn’t flexible or deep enough for my requirements.
So I wrote my own (I blogged about it here): on the one hand I focused on flexibility in terms of how the data can be divided up (with a very versatile strategy/trade/tag system), and on the other hand on producing meaningful and relevant information that can be applied to improve your trading. Now I have ported it to WPF and removed a bunch of proprietary components so it can be open sourced. So…
I’m very happy to announce that the first version (0.1) of the QUSMA Performance Analytics Suite (QPAS) is now available. For an overview of its main performance analysis capabilities see the performance report documentation.
The port is still very fresh so I’d really appreciate your feedback. For bug reports, feature requests, etc. you can either use the GitHub issue tracker, the google group, or the comments on this post.
While the IB flex statements provide enough data for most functionality, QPAS needs additional data for things like charting, execution analysis, and benchmarking. By default it uses QDMS, but you can use your own data source by implementing the IExternalDataSource interface.
Currently the only supported broker is Interactive Brokers, but for those of you who do not use them, the statement importing system is flexible: see the Implementing a Statement Parser page in the documentation for more.
I should note that in general I designed the application for myself and my own style of trading, which means that some features you might expect are missing: no sector/factor attribution for stock pickers, no attribution stats for credit pickers, daily-frequency calculation of things like MAE/MFE (so any intraday trades will show zero MAE/MFE), and no options-specific analytics. All these things would be reasonably easy to add if you feel like it (and know a bit of C#), though.
Features:
- Highly detailed performance statistics
- Ex-post risk analytics
- Benchmarking
- Execution analytics
- Trade journal: annotate trades with rich text and images
Requirements:
Screenshots:
-

-
Performance overview
-

-
Per-trade stats
-

-
Monte Carlo simulation, with equity curve confidence intervals and max drawdown distribution
-

-
Benchmarking
-

-
Execution analysis
-

-
Expected shortfall
-

-
Trade annotations with rich text and images
-

-
Trade overview
-

-
Maximum adverse excursion (MAE)
-

-
Relative capital usage by strategy
-

-
Performance by instrument
-

-
Average cumulative returns per day
Read more Announcing QPAS: Open Source Performance, Risk, and Execution Analytics
Averaging financial time series in a way that preserves important features is an interesting problem, and central in the quest to create good “alpha curves”. A standard average over several time series will usually smooth away the most salient aspects: the magnitude of the extremes and their timing. Naturally, these points are the most important for traders as they give guidance about when and where to trade.
DTW Barycenter Averaging (or DBA) is an iterative algorithm that uses dynamic time warping to align the series to be averaged with an evolving average. It was introduced in A global averaging method for dynamic time warping, with applications to clustering by Petitjean, et. al. As you’ll see below, the DBA method has several advantages that are quite important when it comes to combining financial time series. Note that it can also be used to cluster time series using k-means. Roughly, the algorithm works as follows:
- The n series to be averaged are labeled S1…Sn and have length T.
- Begin with an initial average series A.
- While average has not converged:
- For each series S, perform DTW against A, and save the path.
- Use the paths, and construct a new average A by giving each point a new value: the average of every point from S connected to it in the DTW path.
You can find detailed step-by-step instructions in the paper linked above.
A good initialization process is extremely important because while the DBA process itself is deterministic, the final result depends heavily on the initial average sequence. For our purposes, we have 3 distinct goals:
- To preserve the shape of the inputs.
- To preserve the magnitude of the extremes on the y axis.
- To preserve the timing of those extremes on the x axis.
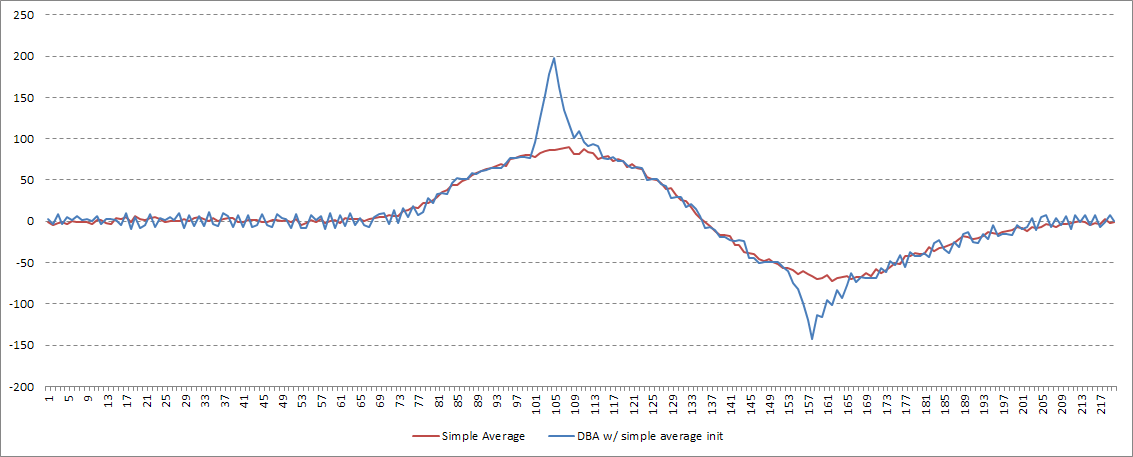
Let’s take a look at how DBA compares to normal averaging, and how the initial average sequence affects the end result. For testing purposes I started out with this series:

Then created a bunch of copies by adding some random variation and an x-axis offset:

To start out, let’s see what a simple average does. Note the shape, the distance between peak and valley, and the magnitude of the minimum and maximum values: all far from the original series.

The simple average fails at all 3 goals laid out above.
Now, on to DBA. What are our initialization options? My first instinct was to try to start the process using the simple average, above. While this achieves goal #2, the overall shape is obviously wrong.

Petitjean et. al. recommend picking one of the input series at random. On the one hand this preserves the shape well, but the timing of the extremes depends on which series happened to be chosen. Additionally, a deterministic process is preferable for obvious reasons.

My solution was to use an input series for initialization, but to choose it through a deterministic process. I first de-trend every timeseries, then record the x-axis value of the y-axis maximum and minimum values for each series. The series that is closest to the median of those values is chosen. This allows us to preserve the shape, the y-axis extreme magnitudes, and get a good idea of the typical x-axis position of those extremes:

You can find C# code to do DBA here.
Read more Reverse Engineering DynamicHedge’s “Alpha Curves”, Part 2.5 of 3: DTW Barycenter Averaging
The QUSMA Data Management System (QDMS) is an application for acquiring, managing, and distributing low-frequency historical and real-time data, written in C#.
QDMS uses a client/server model. The server acts as a broker between clients and external data sources. It also manages metadata on instruments, and local storage of historical data. Finally it also functions as a UI for managing the metadata & data, as well as importing/exporting data from and to CSV files.
Currently it supports two external data sources: Interactive Brokers and Yahoo, but I’ll be adding more in the future.
Note that it’s not “production-ready” right now. There are still a few bugs to iron out, and it also uses unstable 3rd party libraries (the alpha version of the MySQL .NET connector, because it’s the only one that supports Entity Framework 6). All the “core” functionality is implemented and functional, however.
You can find the code here: https://github.com/qusma/qdms. I’m releasing it under the permissive BSD License. Contributions by way of pull requests are more than welcome. If you’d like to make any feature requests or just flame me for the quality of my code, leave a comment right here.
I personally use it in my backtester and portfolio performance evaluation applications, and I’m in the process of integrating it with my live trading app as well.
Using the client is easy, let’s take a look at some code examples:
Getting a list of all instruments:
List<Instrument> instruments = client.FindInstruments();
Searching for a specific instrument, for example SPY:
Instrument spy = client.FindInstruments(new Instrument { Symbol = "SPY" }).FirstOrDefault();
Requesting historical data:
var histRequest = new HistoricalDataRequest(
spy,
BarSize.OneDay,
new DateTime(2013, 1, 1),
new DateTime(2013, 1, 15));
client.RequestHistoricalData(histRequest);
Requesting real time data:
var rtRequest = new RealTimeDataRequest(spy, BarSize.OneSecond);
client.RequestRealTimeData(rtRequest);
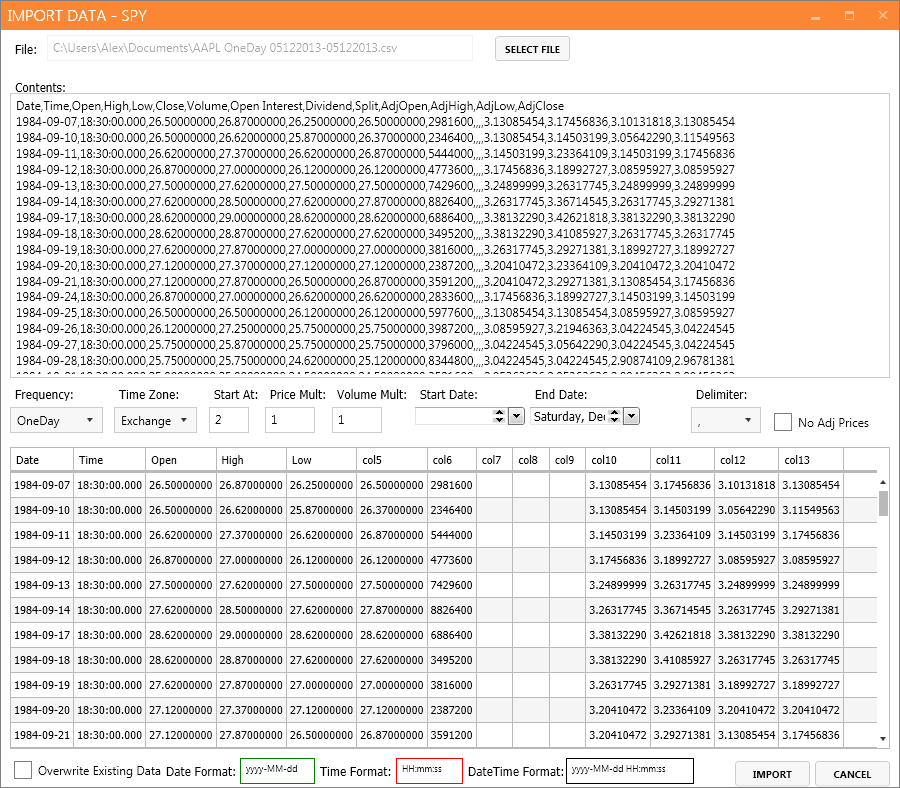
Some screenshots:

Instrument metadata.

Adding a new instrument from Interactive Brokers.

Importing data from a CSV file.

Main server screen.
Read more The QUSMA Data Management System Is Now Open Source
The .NET ecosystem is rich with excellent, free libraries that cover pretty much everything you need when writing trading software. So here’s a collection of libraries I use in my applications, mostly focused on stats, math, and machine learning but also including time handling, data structures, and calendars:
Based on the Aforge.NET library, it offers tons of useful stuff for traders: matrices, descriptive statistics, probability distributions, optimization methods, regression, PCA, as well as a wide array of machine learning algorithms. I use it all the time.
Tons of useful math and stats functions, matrices & linear algebra (very fast), PCA, regression, unsupervised machine learning.
Probability distributions & random number generation, linear algebra, simple statistical analysis, various useful math functions.
Various extremely useful data structures: double ended queue, dictionary with multiple values per key, red-black tree, ordered dictionary/list.
A port of quantlib to C#. Not just derivatives, there’s a lot of useful stuff in here such as calendars with holidays for a very wide array of markets. There’s also NQuantLib which I haven’t tried.
Time handling done right. You need this.
Lets you use R from your .NET applications. Slow, buggy as hell, hard to work with, but some times it’s very useful to have access to some of the more obscure/specialized R libraries.
Regression, some machine learning, PCA, optimization, and linear algebra, simple hypothesis testing.
There are several commercial options available as well, such as Extreme Optimization and NMath. I haven’t used either of them so I can’t comment on their quality.
Read more Useful and Free C#/.NET Libraries for Traders
Posting has been slow lately because I’ve been busy with a bunch of other stuff, including the CFA Level 3 exam last weekend. I’ve also begun work on a very ambitious project: a fully-featured all-in-one backtesting and live trading suite, which is what prompted this post.
Over the last half year or so I’ve been moving toward more complex tools (away from excel, R, and MATLAB), and generally just writing standalone backtesters in C# for every concept I wanted to try out, only using Multicharts for the simplest ideas. This approach is, of course, incredibly inefficient, but the software packages available to “retail” traders are notoriously horrible, and I have nowhere near the capital I’d need to afford “real” tools like QuantFACTORY or Deltix.
The good thing about knowing how to code is that if a tool doesn’t exist you can just write it, and that’s exactly what I’m doing. Proper portfolio-level backtesting and live trading that’ll be able to easily do everything from intraday pairs trading to long term asset allocation and everything in-between, all under the same roof. On the other hand it’s also tailored to my own needs, and as such contains no plans for things like handling fundamental data. Most importantly it’s my dream research platform that’ll let me go from idea, to robust testing & optimization, to implementation very quickly. Here’s what the basic design looks like:

What’s the point of posting about it? I know there are many other people out there facing the same issues I am, so hopefully I can provide some inspiration and ideas on how to solve them. Maybe it’ll prompt some discussion and idea-bouncing, or perhaps even collaboration.
Most of the essential stuff has already been laid down, so basic testing is already possible. A simple example based on my previous post can showcase some essential features. Below you’ll find the code behind the PatternFinder indicator, which uses the Accord.NET library’s k-d tree and k nearest neighbor algorithm implementation to do candlestick pattern searches as discussed here. Many elements are specific to my system, but the core functionality is trivially portable if you want to borrow it.
Note the use of attributes to denote properties as inputs, and set their default values. Options can be serialized/deserialized for easy storage in files or a database. Priority settings allow the user to specify the order of execution, which can be very important in some cases. Indexer access works with [0] being the current bar, [1] being the previous bar, etc. Different methods for historical and real time bars allow for a ton of optimization to speed up processing when time is scarce, though in this case there isn’t much that can be done.

The VariableSeries class is designed to hold time series, synchronize them across the entire parent object, prevent data snooping, etc. The Indicator and Signal classes are all derived from VariableSeries, which is the basis for the system’s modularity. For example, in the PatternFinder indicator, OHLC inputs can be modified by the user through the UI, e.g. to make use of the values of an indicator rather than the instrument data.

The backtesting analysis stuff is still in its early stages, but again the foundations have been laid. Here are some stats using a two-day PatternFinder combined with IBS, applied on SPY:
![showcase_patternfinderresults2[1]](https://i1.wp.com/qusma.com/wp-content/uploads/2013/06/showcase_patternfinderresults21.png?resize=1140%2C563&ssl=1)
Here’s the first iteration of the signal analysis interface. I have added 3 more signals to the backtest: going long for 1 day at every 15 day low close, the set-up Rob Hanna posted yesterday over at Quantifiable Edges (staying in for 5 days after the set-up appears), and UDIDSRI. The idea is to be able to easily spot redundant set-ups, find synergies or anti-synergies between signals, and easily get an idea of the marginal value added by any one particular signal.

And here’s some basic Monte Carlo simulation stuff, with confidence intervals for cumulative returns and PDF/CDF of the maximum drawdown distribution:

Here’s the code for the PatternFinder indicator. Obviously it’s written for my platform, but it should be easily portable. The “meat” is all in CalcHistorical() and GetExpectancy().
/// <summary>
/// K nearest neighbor search for candlestick patterns
/// </summary>
public class PatternFinder : Indicator
{
[Input(3)]
public int PatternLength { get; set; }
[Input(75)]
public int MatchCount { get; set; }
[Input(2000)]
public int MinimumWindowSize { get; set; }
[Input(false)]
public bool VolatilityAdjusted { get; set; }
[Input(false)]
public bool Overnight { get; set; }
[Input(false)]
public bool WeighExpectancyByDistance { get; set; }
[Input(false)]
public bool Classification { get; set; }
[Input(0.002)]
public double ClassificationLimit { get; set; }
[Input("Euclidean")]
public string DistanceType { get; set; }
[SeriesInput("Instrument.Open")]
public VariableSeries<decimal> Open { get; set; }
[SeriesInput("Instrument.High")]
public VariableSeries<decimal> High { get; set; }
[SeriesInput("Instrument.Low")]
public VariableSeries<decimal> Low { get; set; }
[SeriesInput("Instrument.Close")]
public VariableSeries<decimal> Close { get; set; }
[SeriesInput("Instrument.AdjClose")]
public VariableSeries<decimal> AdjClose { get; set; }
private VariableSeries<double> returns;
private VariableSeries<double> stDev;
private KDTree<double> _tree;
public PatternFinder(QSwing parent, string name = "PatternFinder", int BarsCount = 1000)
: base(parent, name, BarsCount)
{
Priority = 1;
returns = new VariableSeries<double>(parent, BarsCount);
stDev = new VariableSeries<double>(parent, BarsCount) { DefaultValue = 1 };
}
internal override void Startup()
{
_tree = new KDTree<double>(PatternLength * 4 - 1);
switch (DistanceType)
{
case "Euclidean":
_tree.Distance = Accord.Math.Distance.Euclidean;
break;
case "Absolute":
_tree.Distance = AbsDistance;
break;
case "Chebyshev":
_tree.Distance = Accord.Math.Distance.Chebyshev;
break;
default:
_tree.Distance = Accord.Math.Distance.Euclidean;
break;
}
}
public override void CalcHistorical()
{
if (VolatilityAdjusted && CurrentBar > 0)
returns.Value = (double)(AdjClose[0] / AdjClose[1] - 1);
if (VolatilityAdjusted && CurrentBar > 11)
stDev.Value = returns.StandardDeviation(10);
if (CurrentBar < PatternLength + 1) return;
if (CurrentBar > MinimumWindowSize)
Value = GetExpectancy(GetCoords());
double ret = Overnight ? (double)(Open[0] / Close[1] - 1) : (double)(AdjClose[0] / AdjClose[1] - 1);
double adjret = ret / stDev[0];
if (Classification)
_tree.Add(GetCoords(1), adjret > ClassificationLimit ? 1 : 0);
else
_tree.Add(GetCoords(1), adjret);
}
public override void CalcRealTime()
{
if (VolatilityAdjusted && CurrentBar > 0)
returns.Value = (double)(AdjClose[0] / AdjClose[1] - 1);
if (VolatilityAdjusted && CurrentBar > 11)
stDev.Value = returns.StandardDeviation(10);
if (CurrentBar > MinimumWindowSize)
Value = GetExpectancy(GetCoords());
}
private double GetExpectancy(double[] coords)
{
if (!WeighExpectancyByDistance)
return _tree.Nearest(coords, MatchCount).Average(x => x.Node.Value) * stDev[0];
else
{
var nodes = _tree.Nearest(coords, MatchCount);
double totweight = nodes.Sum(x => 1 / Math.Pow(x.Distance, 2));
return nodes.Sum(x => x.Node.Value * ((1 / Math.Pow(x.Distance, 2)) / totweight)) * stDev[0];
}
}
private static double AbsDistance(double[] x, double[] y)
{
return x.Select((t, i) => Math.Abs(t - y[i])).Sum();
}
private double[] GetCoords(int offset = 0)
{
double[] coords = new double[PatternLength * 4 - 1];
for (int i = 0; i < PatternLength; i++)
{
coords[4 * i] = (double)(Open[i + offset] / Close[i + offset]);
coords[4 * i + 1] = (double)(High[i + offset] / Close[i + offset]);
coords[4 * i + 2] = (double)(Low[i + offset] / Close[i + offset]);
if (i < PatternLength - 1)
coords[4 * i + 3] = (double)(Close[i + offset] / Close[i + 1 + offset]);
}
return coords;
}
}
Coming up Soon™: a series of posts on cross validation, an in-depth paper on IBS, and possibly a theory-heavy paper on the low volatility effect.
Read more Blueprint for a Backtesting and Trading Software Suite











![showcase_patternfinderresults2[1]](https://i1.wp.com/qusma.com/wp-content/uploads/2013/06/showcase_patternfinderresults21.png?ssl=1)

