Averaging financial time series in a way that preserves important features is an interesting problem, and central in the quest to create good “alpha curves”. A standard average over several time series will usually smooth away the most salient aspects: the magnitude of the extremes and their timing. Naturally, these points are the most important for traders as they give guidance about when and where to trade.
DTW Barycenter Averaging (or DBA) is an iterative algorithm that uses dynamic time warping to align the series to be averaged with an evolving average. It was introduced in A global averaging method for dynamic time warping, with applications to clustering by Petitjean, et. al. As you’ll see below, the DBA method has several advantages that are quite important when it comes to combining financial time series. Note that it can also be used to cluster time series using k-means. Roughly, the algorithm works as follows:
- The n series to be averaged are labeled S1…Sn and have length T.
- Begin with an initial average series A.
- While average has not converged:
- For each series S, perform DTW against A, and save the path.
- Use the paths, and construct a new average A by giving each point a new value: the average of every point from S connected to it in the DTW path.
You can find detailed step-by-step instructions in the paper linked above.
A good initialization process is extremely important because while the DBA process itself is deterministic, the final result depends heavily on the initial average sequence. For our purposes, we have 3 distinct goals:
- To preserve the shape of the inputs.
- To preserve the magnitude of the extremes on the y axis.
- To preserve the timing of those extremes on the x axis.
Let’s take a look at how DBA compares to normal averaging, and how the initial average sequence affects the end result. For testing purposes I started out with this series:

Then created a bunch of copies by adding some random variation and an x-axis offset:

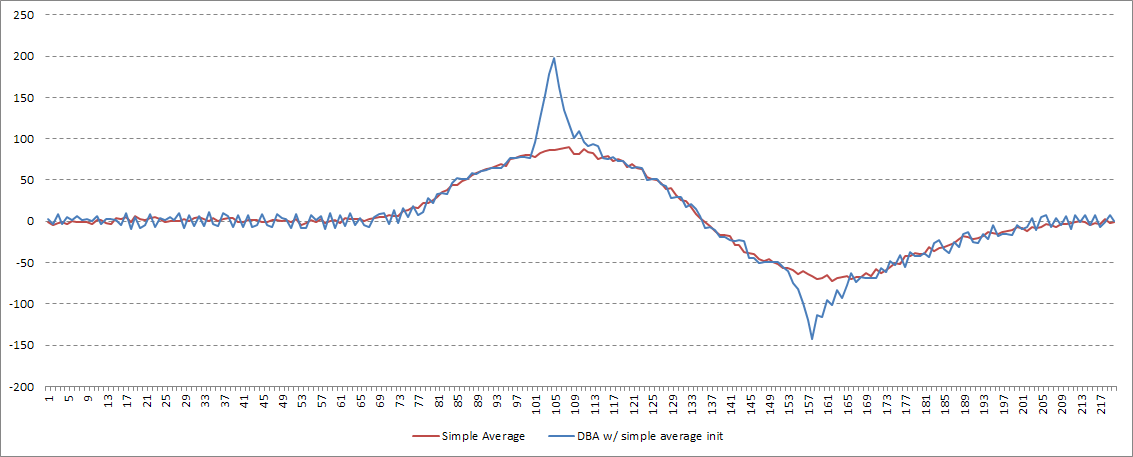
To start out, let’s see what a simple average does. Note the shape, the distance between peak and valley, and the magnitude of the minimum and maximum values: all far from the original series.

The simple average fails at all 3 goals laid out above.
Now, on to DBA. What are our initialization options? My first instinct was to try to start the process using the simple average, above. While this achieves goal #2, the overall shape is obviously wrong.

Petitjean et. al. recommend picking one of the input series at random. On the one hand this preserves the shape well, but the timing of the extremes depends on which series happened to be chosen. Additionally, a deterministic process is preferable for obvious reasons.

My solution was to use an input series for initialization, but to choose it through a deterministic process. I first de-trend every timeseries, then record the x-axis value of the y-axis maximum and minimum values for each series. The series that is closest to the median of those values is chosen. This allows us to preserve the shape, the y-axis extreme magnitudes, and get a good idea of the typical x-axis position of those extremes:

You can find C# code to do DBA here.
Read more Reverse Engineering DynamicHedge’s “Alpha Curves”, Part 2.5 of 3: DTW Barycenter Averaging
In the first part of the series we covered dynamic time warping. Here we look at clustering. K-means clustering is probably the most popular method, mainly due to its simplicity and intuitive algorithm. However it has some drawbacks that make it a bad choice when it comes to clustering time series. Instead, we’ll use K-medoids clustering.
The main conceptual difference between K-means and K-medoids is the distance used in the clustering algorithm. K-means uses the distance from a centroid (an average of the points in the cluster), while K-medoids uses distance from a medoid, which is simply a point selected from the data. The algorithms used for arriving at the final clusters are quite different.

K-medoid clustering depends on distances from k (in this case 2) points drawn from the data.

K-means distances are taken from a centroid which is created by averaging the points in that cluster.
How does K-medoids compare to K-means? It has several features that make it superior for most problems in finance.
- K-medoids is not sensitive to outliers that might “pull” the centroid to a disadvantageous position.
- K-medoids can handle arbitrary distance functions. Unlike K-means, there is no need for a mean to be defined.
- Unlike K-means, K-medoids has no problems with differently-sized clusters.
- K-medoids is also potentially less computationally intensive when the distance function is difficult to solve, as distances only need to be computed once for each pair of points.
Note that there’s no guarantee on the size of each cluster. If you want to, it’s trivial to add some sort of penalty function to force similarly-sized clusters.
The algorithm is simple:
- Choose k points from the sample to be the initial medoids (see below for specific methods).
- Give cluster labels to each point in the sample based on the closest medoid.
- Replace the medoids with some other point in the sample. If the total cost (sum of distances from the closest medoid) decreases, keep this new confirugration.
- Repeat until there is no further change in medoids.
Initialization, i.e. picking the initial clusters before the algorithm is run, is an important issue. The final result is sensitive to the initial set-up, as the clustering algorithm can get caught in local minimums. It is possible to simply assign labels at random and repeat the algorithm multiple times. I prefer a deterministic initialization method: I use a procedure based on Park et al., the code for which you can find further down. The gist of it is that it selects the first medoid to be the point with the smallest average distance to all other points, then selects the remaining medoids based on maximum distance from the previous medoids. It works best when k is set to (or at least close to) the number of clusters in the data.
An example, using two distinct groups (and two outliers):

Initial medoids with k=2.
The first medoid is selected due to its closeness to the rest of the points in the lower left cluster, then the second one is selected to be furthest away from the first one, thus “setting up” the two obvious clusters in the data.
In terms of practical applications, clustering can be used to group candlesticks and create a transition matrix (also here), to group and identify trading algorithms, or for clustering returns series for forecasting (also here). I imagine there’s some use in finding groups of similar assets for statistical arbitrage, as well.
Something I haven’t seen done but I suspect has potential is to cluster trades based on return, length, adverse excursion, etc. Then look at the average state of the market (as measured by some indicators) in each cluster, the most common industries of the stocks in each cluster, or perhaps simply the cumulative returns series of each trade at a reasonably high frequency. Differences between the “good trades” cluster(s) and the “bad trades” cluster(s) could then be used to create filters. The reverse, clustering based on conditions and then looking at the average returns in each cluster would achieve the same objective.
I wrote a simple K-medoids class in C#, which can handle arbitrary data types and distance functions. You can find it here. I believe there are packages for R and python if that’s your thing.
Read more Reverse Engineering DynamicHedge’s “Alpha Curves”, Part 2 of 3: K-Medoids Clustering
DynamicHedge recently introduced a new service called “alpha curves”: the main idea is to find patterns in returns after certain events, and present the most frequently occurring patterns. In their own words, alpha curves “represent a special blend of uniqueness and repeatability”. Here’s what they look like, ranked in order of “pattern dominance”. According to them, they “use different factors other than just returns”. We can speculate about what other factors go into it, possibly something like maximum extension or the timing of maxima and minima, but I’ll keep it simple and only use returns.
In this post I’ll do a short presentation of dynamic time warping, a method of measuring the similarity between time series. In part 2 we will look at a clustering method called K-medoids. Finally in part 3 we will put the two together and generate charts similar to the alpha curves. The terminology might be a bit intimidating, but the ideas are fundamentally highly intuitive. As long as you can grasp the concepts, the implementation details are easy to figure out.
To be honest I’m not so sure about the practical value of this concept, and I have no clue how to quantify its performance. Still, it’s an interesting idea and the concepts that go into it are useful in other areas as well, so this is not an entirely pointless endeavor. My backtesting platform still can’t handle intraday data properly, so I’ll be using daily bars instead, but the ideas are the same no matter the frequency.
So, let’s begin with why we need DTW at all in the first place. What can it do that other measures of similarity, such as Euclidean distance and correlation can not? Starting with correlation: one must keep in mind that it is a measure of similarity based on the difference between means. Significantly different means can lead to high correlation, yet strikingly different price series. For example, the returns of these two series have a correlation of 0.81, despite being quite dissimilar.

A second issue, comes up in the case of slightly out of phase series, which are very similar but can have low correlations and high Euclidean distances. The returns of these two curves have a correlation of .14:

So, what is the solution to these issues? Dynamic Time Warping. The main idea behind DTW is to “warp” the time series so that the distance measurement between each point does not necessarily require both points to have the same x-axis value. Instead, the points further away can be selected, so as to minimize the total distance between the series. The algorithm (the original 1987 paper by Sakoe & Chiba can be found here) restricts the first and last points to be the beginning and end of each series. From there, the matching of points can be visualized as a path on an n by m grid, where n and m are the number of points in each time series.

Source: Elena Tsiporkova, Dynamic Time Warping Algorithm for Gene Expression Time Series
The algorithm finds the path through this grid that minimizes the total distance. The function that measures the distance between each set of points can be anything we want. To restrict the number of possible paths, we restrict the possible points that can be connected, by requiring the path to be monotonically increasing, limiting the slope, and restricting how far away from a straight line the path can stray. The difference between standard Euclidean distance and DTW can be demonstrated graphically. In this case I use two sin curves. The gray lines between the series show which points the distance measurements are done between.

DTW

Euclidean
Notice the warping at the start and end of the series, and how the points in the middle have identical y-values, thus minimizing the total distance.
What are the practical applications of DTW in trading? As we’ll see in the next parts, it can be used to cluster time series. It can also be used to average time series, with the DBA algorithm. Another potential use is k-nn pattern matching strategies, which I have experimented with a bit…some quick tests showed small but persistent improvements in performance over Euclidean distance.
If you want to test it out yourselves, there are plenty of tools out there. I’m using the NDTW .NET library. There are libraries available for R and python as well.
Read more Reverse Engineering DynamicHedge’s Alpha Curves, Part 1 of 3: Dynamic Time Warping













{kind=link}