Averaging financial time series in a way that preserves important features is an interesting problem, and central in the quest to create good “alpha curves”. A standard average over several time series will usually smooth away the most salient aspects: the magnitude of the extremes and their timing. Naturally, these points are the most important for traders as they give guidance about when and where to trade.
DTW Barycenter Averaging (or DBA) is an iterative algorithm that uses dynamic time warping to align the series to be averaged with an evolving average. It was introduced in A global averaging method for dynamic time warping, with applications to clustering by Petitjean, et. al. As you’ll see below, the DBA method has several advantages that are quite important when it comes to combining financial time series. Note that it can also be used to cluster time series using k-means. Roughly, the algorithm works as follows:
- The n series to be averaged are labeled S1…Sn and have length T.
- Begin with an initial average series A.
- While average has not converged:
- For each series S, perform DTW against A, and save the path.
- Use the paths, and construct a new average A by giving each point a new value: the average of every point from S connected to it in the DTW path.
You can find detailed step-by-step instructions in the paper linked above.
A good initialization process is extremely important because while the DBA process itself is deterministic, the final result depends heavily on the initial average sequence. For our purposes, we have 3 distinct goals:
- To preserve the shape of the inputs.
- To preserve the magnitude of the extremes on the y axis.
- To preserve the timing of those extremes on the x axis.
Let’s take a look at how DBA compares to normal averaging, and how the initial average sequence affects the end result. For testing purposes I started out with this series:

Then created a bunch of copies by adding some random variation and an x-axis offset:

To start out, let’s see what a simple average does. Note the shape, the distance between peak and valley, and the magnitude of the minimum and maximum values: all far from the original series.

The simple average fails at all 3 goals laid out above.
Now, on to DBA. What are our initialization options? My first instinct was to try to start the process using the simple average, above. While this achieves goal #2, the overall shape is obviously wrong.
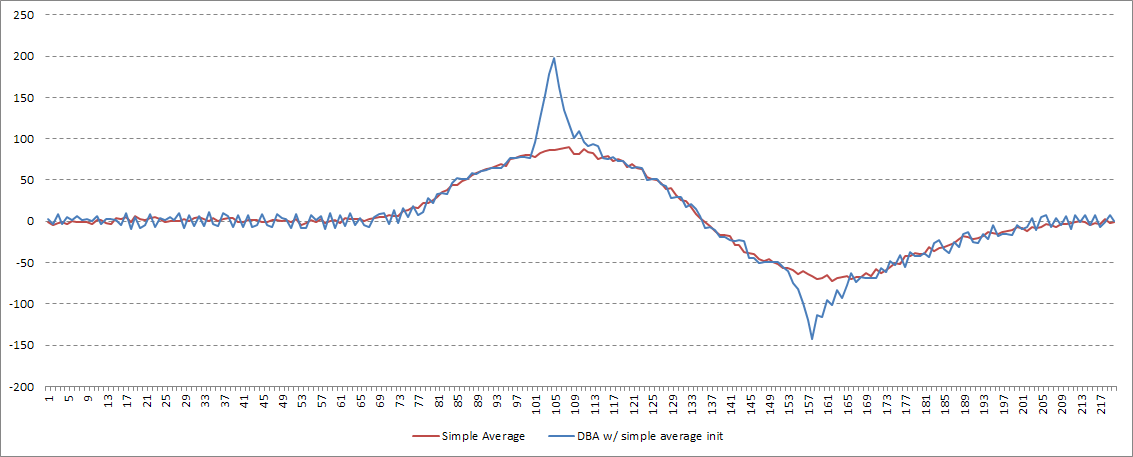
Petitjean et. al. recommend picking one of the input series at random. On the one hand this preserves the shape well, but the timing of the extremes depends on which series happened to be chosen. Additionally, a deterministic process is preferable for obvious reasons.

My solution was to use an input series for initialization, but to choose it through a deterministic process. I first de-trend every timeseries, then record the x-axis value of the y-axis maximum and minimum values for each series. The series that is closest to the median of those values is chosen. This allows us to preserve the shape, the y-axis extreme magnitudes, and get a good idea of the typical x-axis position of those extremes:

You can find C# code to do DBA here.
Reverse Engineering DynamicHedge’s “Alpha Curves”, Part 2 of 3: K-Medoids Clustering says:
[…] Reverse Engineering DynamicHedge’s “Alpha Curves”, Part 2.5 of 3: DTW Barycenter A… […]
Reverse Engineering DynamicHedge’s Alpha Curves, Part 1 of 3: Dynamic Time Warping says:
[…] Reverse Engineering DynamicHedge’s “Alpha Curves”, Part 2.5 of 3: DTW Barycenter A… […]
booromand says:
The performance is very good
راهبند اتوماتیک–کرکره برقی–لامپ کم مصرف–درب ضد سرقت
Kevin Jin says:
Although this algorithm works pretty well with stationary time series, I’ve found that it seems to have strange results when using it on random walks. That’s usually not a problem because economic time series are usually unit roots so you can simply first difference the prices (i.e. calculate returns) and run DBA on the resulting time series.
Kevin Jin says:
Although this algorithm works pretty well with stationary time series, I’ve found that it seems to have strange results when using it on random walks. That’s usually not a problem because economic time series are usually unit roots so you can simply first difference the prices (i.e. calculate returns) and run DBA on the resulting time series.
Kevin Jin says:
And here is the result of untransforming the average time series of the returns, i.e. performing an “diffinv” of the returns and using the average of the initial prices of stocks X and Y for the initial price of the average time series. You can see the average creeping over X, which is expected since the gap between X and Y decreases over time. There’s probably a better way of calculating the initial price of the average time series as to minimize the number of times the average falls outside the area between X and Y.